AI now does a competent first pass at all of it in seconds. That feels like a threat until you notice what it did not take. It did not take the judgment about which numbers carry the decision, and it did not take responsibility for being right or wrong.
Everyone wants to be the pilot. Sadly, your job doesn't involve wearing a shiny uniform with a fancy hat. Or maybe you do it anyway.
Or... maybe this post should have started with: "It is Sunday night. The investment committee meets at nine." IC meetings Monday at 9?!
The thing is, since we have AI, people do the work later. Last minute.
So you paste 180 boring pages of the Boring ThisAndThat Inc. annual report into the AI and ask "the Model" for a read. Ten seconds later you get a clean summary: revenue up 6%, margins steady, free cash flow growing fast, and the dividend well covered.
The verdict was a confident buy. It was well written. You almost pasted it into the deck.
Then one number does not trace.
"I made a mistake" (AI)
The summary said free cash flow rose 18% to 240 million EUR. You went looking for that line in the report. It was not there. The cash flow statement showed operating cash flow of 310 million and capital expenditure of 120 million. That is 190 million of free cash flow, not 240. The model didn't read a number. It had produced one. A hallucination.
This is a moment many analysts have already had with an AI, and the moment that decides whether the tool makes them better or just faster at being wrong. The fix is not a better prompt. It is a different way of flying.
Many Quants remember a similar problem: the 2007 Quant Quakes. You can be fast at being wrong. Too fast = wrong.
The summary that reads like a landing
A one-shot summary is seductive because it is fluent. Fluency reads as competence. The AI model wrote in the calm, hedged register of a senior analyst, so the brain that reads it grants it a senior analyst's credibility. None of that fluency is evidence that the numbers are in the report.
The common defense is that the model read the whole filing, so its summary must be grounded in it. That is the wrong mental model. A language model is trained to produce text that sounds right, not text that is traceable to a source. Most of the time those two things overlap. The 18% number is what happens when they do not. It sounded exactly like a free cash flow figure should sound. It just did not come from anywhere.
Pilots do not trust autopilot. They trust the checklist.
Commercial pilots fly most of a long haul on autopilot. They are not nervous about this, and they are not heroes for using it. They trust the automation precisely because they are trained for the minutes when it fails. The training does not assume the autopilot is perfect. It assumes the opposite, and builds the catch into procedure: cross-checks, callouts, and a checklist that does not care how confident anyone feels.
Current AI trainings don't produce this level of awareness.
AI can make mistakes.
(Sherlock)
Experience produces awareness. And once the experience is there, that is the posture to copy. The AI is the autopilot. It is genuinely good and it will genuinely fail, and the failure is not a scandal. It is the expected case you fly around.
In the cockpit
In the analysis
Why it holds
Autopilot flies the cruise
The model drafts the summary and the first-pass numbers
Fast, tireless, right most of the time. Worth using.
Automation will fail, and that is assumed
The model will state a number that is not in the report
You plan for the failure instead of being shocked by it.
The checklist does not care how the crew feels
The audit trace does not care how confident the prose sounds
A procedure catches what judgment under time pressure misses.
Two pilots cross-check the critical calls
You trace the load-bearing numbers, not every line
Effort goes where a wrong number changes the decision.
The pilot, not the autopilot, signs for the flight
Your name is on the recommendation, not the model's
Accountability does not transfer to the tool.
The number that had no alibi
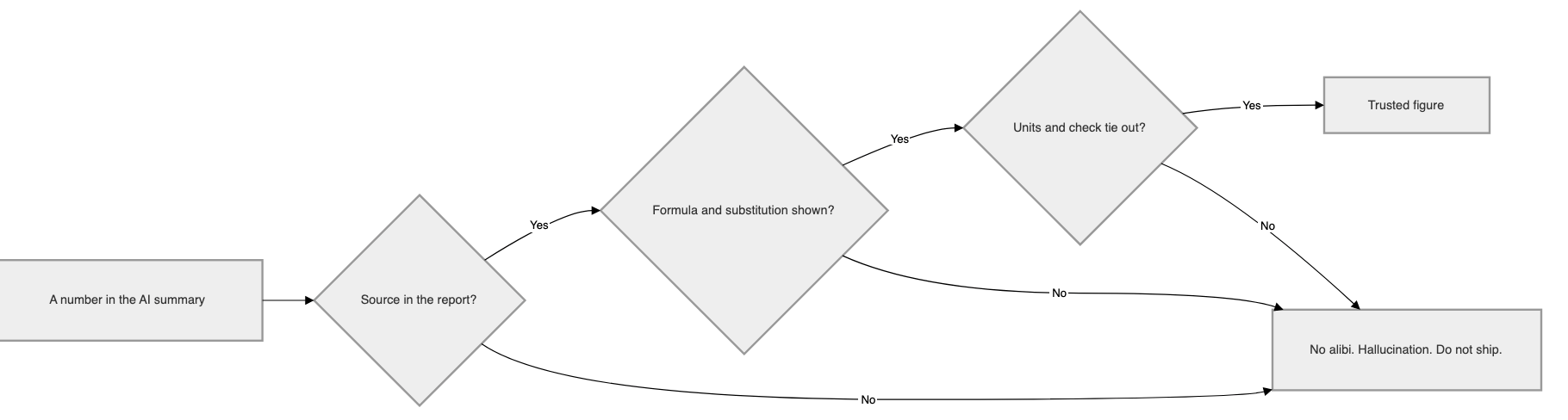
The checklist for a stated number is short. Every figure that carries weight has to answer six questions before you believe it:
where is it from
what formula produced it
what values went in
what came out
in what units, and
does it tie out against something you trust.
A number that cannot answer all six is not a result. It is a placeholder wearing a result's clothes. A hallucination.
You run the Boring Inc. summary through it. Most numbers pass without trouble. One does not.
Stated number
Source
Formula and substitution
Result / units
Check
Revenue 1,820m, +6%
Income statement, p.74
reported figure
1,820 EURm
Ties to IS
Operating cash flow 310m
Cash flow statement, p.88
reported figure
310 EURm
Ties to CF
Capex 120m
Cash flow statement, p.88
reported figure
120 EURm
Ties to CF
Free cash flow 240m, +18%
Not in the report
FCF = OCF - Capex = 310 - 120
= 190, not 240
FAILS: no source, does not tie out
The free cash flow line has no alibi. There is no page to point to, and the one defensible formula gives 190 million, not 240. The dividend-coverage story the summary told was built on the gap between those two numbers. Ship it and you have recommended a buy on cash flow that is 26% smaller than claimed, in front of the committee, with your name on it.
The trace gate. A number that cannot name its source bounces out before it reaches the deck.
Stop one-shotting. Fly the loop.
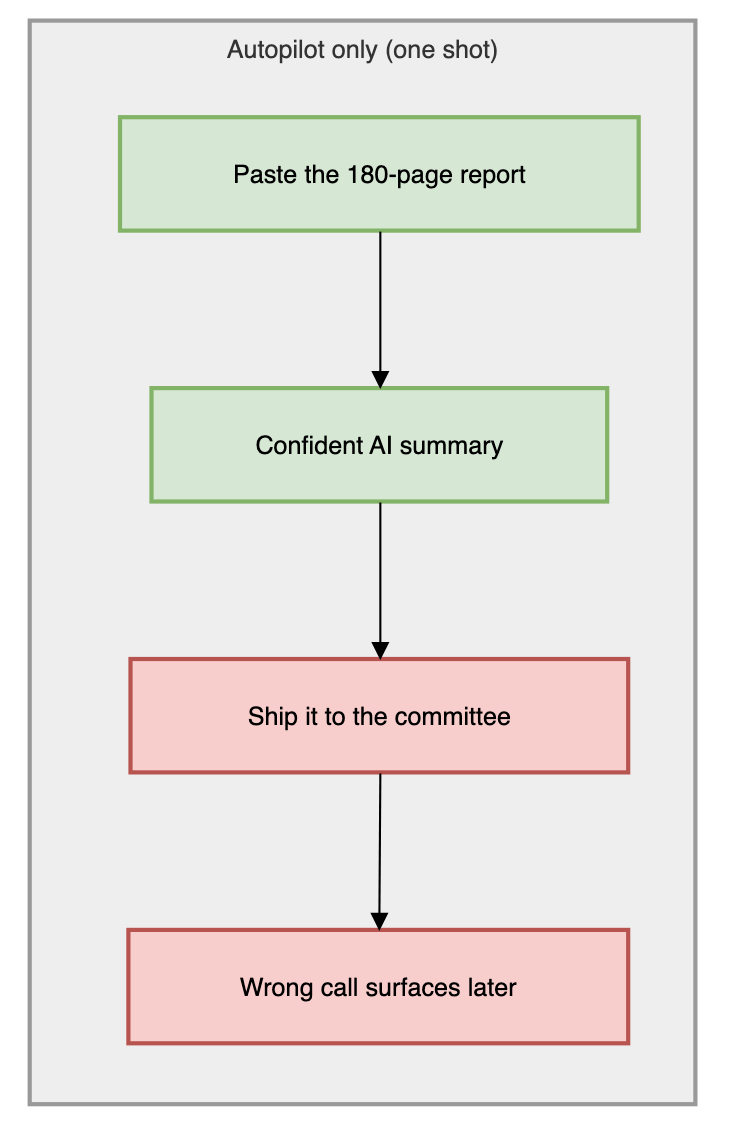
One-shot prompting asks the model for the answer and treats what comes back as the answer. It is a single call with no cross-check, and it disappoints for the same reason a co-pilot who never speaks up would: nobody caught the slip. The disappointment then gets blamed on the model, when the real fault was the workflow that shipped its first draft.
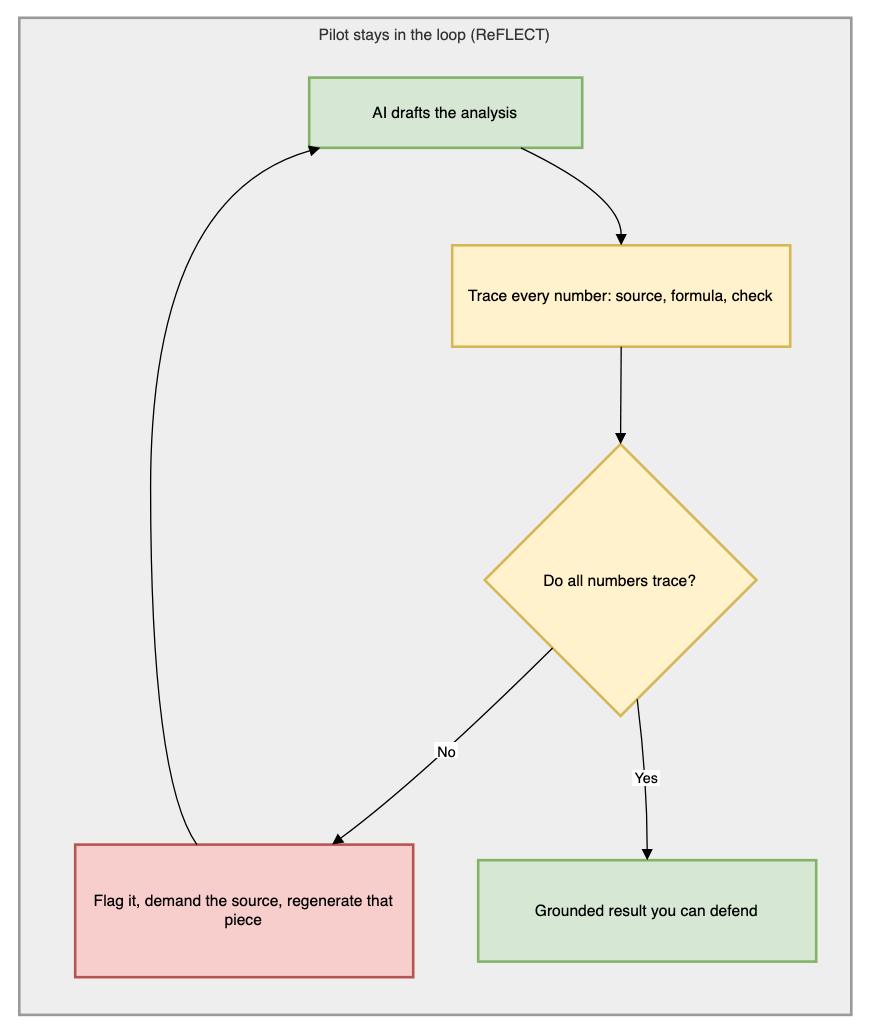
The loop is different. You ask the model to draft. You trace the load-bearing numbers. When one fails, you do not throw out the tool and you do not quietly fix the number yourself. You hand the failure back: name the line, ask where it came from, ask it to recompute from the statement. The result gets built across a few exchanges instead of demanded in one. That is the same move a good editor makes with a fast junior, or a good pilot makes with the automation. Stay in the loop, keep the parts that hold, send back the parts that do not.
Two ways to fly the same report. The top path ships the first draft. The bottom path loops until every number can defend itself.
There is a fair objection. Tracing numbers is slower than reading a summary, and the whole point of the AI tool was speed. Silicon instead of headcount. True for the lines that do not matter, which is why you do not trace them. You trace the ones the recommendation rests on. Measured against the cost of defending a wrong call to the committee, or quietly revising a published note, the loop is the fast path. One-shot results only look faster until the number that did not trace is the one everyone remembers.
Your edge moved
For most of the job's history, the analyst's scarce skill was producing the numbers: pulling the filing apart, building the model, getting the arithmetic right. The model now does a competent first pass at all of it in seconds. That feels like a threat until you notice what it did not take. It did not take the judgment about which numbers carry the decision, and it did not take responsibility for being right or wrong.
✈️
The model produces numbers. You interrogate them. That second job is the one that pays, and it is the one the automation cannot sign for.
So treat the AI like the autopilot it is. Let it fly the cruise. Expect it to slip, because that is normal, not because it is broken. Keep your hand near the controls and run the checklist on the calls that matter. The analyst who does this is not slower or more timid than the one who ships the one-shot. They are the ones whose buy recommendation still holds when someone on the committee asks where the free cash flow number came from.
Next report, before you believe the verdict, pick the three numbers the decision rests on and trace them. Source, formula, check. If one will not trace, you have already earned the loop.
Release Corporate Finance Skill (free)
With all of that in mind, here is a Corporate Finance Skill.
Starts with intent, not features. Pick what you're doing (build, analyze, advise, or reflect) and the skill pulls the matching explanation plus the right spreadsheet structure. No guessing which doc to open.
MODEL/BUILD. Three-statement models, budgets, 13-week cash flows, DCF/WACC, ratio dashboards, EBITDA bridges. Output as XLSX or Claude for Excel workbooks.
ANALYZE/DIAGNOSE. Common-size, ratio, and trend analysis on statements you already have.
ADVISE/CONSULT. Helps you choose a valuation method or budgeting method, surface EBITDA levers, and find cash levers.
REFLECT. Stress-tests terminal value, runs sensitivity, and flags Non-GAAP and manipulation risks before a number leaves your hands.
Stays on intent. Once you pick a lane, the workflow holds it until the output and its checks are done. It won't drift mid-task.
Ten references ship with it: EBITDA, ratios and analysis, the three-statement model, cash flow and working capital, DCF/WACC valuation, budgeting, modeling best practices, spreadsheet conventions, auditability/math rigor, and the intent map. Six fill-in asset specs come alongside.
Workbook rules are blunt. Schedules first. Blue cells for starting amounts, yellow for assumptions, formula cells left alone. Dedicated assumptions/instructions and Evidence & Audit Trail sheets. Validation checks built in. No hardcoded values.
Every material number proves itself. Source, formula, substitution, result, units, check. No fact without the trail.
Hands off cleanly. Reflection goes to premortem and reflect. Visuals go to drawio and intana-viz. Rolling findings out to people goes to cobesy.
Disclaimer: The Skill content is built from personal notes on Bojan Radojicic / bojanfin.com materials and MBA financial-modeling materials. Not excerpts from the originals.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.